
Bienvenidos sean a este post, hoy veremos la teoria sobre como recomendar algo.
Hace unos cuantos posts atras, hablamos sobre como aplicar IA o ML mediante C++, todo en forma teorica, y con lo comentado en los ultimos posts podemos decir que un engine de recomendacion puede ser tratado como una solucion conducida por IA o una simple coleccion de instrucciones condicionales.
Desarrollar un sistema que utiliza los datos del usuario y devuelve las opciones que mejor satisfagan lo que se ingreso es una tarea compleja. Sin embargo, debemos tener en cuenta que un engine de recomendacion comprende una lista de reglas por la cual el dato es procesado antes de pasar la salida al usuario. Por ejemplo, las bases de datos de peliculas sugieren nuevas peliculas basadas en las que previamente vimos o valoramos. Una cosa que no tenemos en cuenta es que un engine de recomendaciones es parte de un engine de busqueda.
Llevemos esto a la plataforma de e-commerce, donde usualmente te sugieren productos. Por lo general, siempre tendremos un panel en el producto que buscamos titulado como «Personas que compraron este producto, tambien compraron». En este post, hablamos sobre clustering y esto puede ayudarnos sobre sugerir sobre los elementos del engine mediante algoritmos de clustering.
Pero esto no se aplica solo al e-commerce sino que tambien para cualquier buscador, tomemos nuevamente el caso de google. Cuando hacemos una busqueda cualquiera tendremos una respuesta simillar a esta:

En un costado, si usan un navegador en una computadora, nos mostrara un breve resumen sobre lo que buscamos. Entre ella son varias imagenes y el encabezado de la informacion de la wikipedia con la opcion de poder acceder a esta pagina. Pero tambien tenemos un panel debajo de este:

Estas sugerencias pueden estar basadas por varias situaciones. Desde nuestro historial de busqueda hasta lenguajes relacionados a este, ya sea por su estructura o que lo tomen como base. Esto que utiliza google suele denominarse como grafico de conocimiento (knowledge graph). Este consiste de nodos, los cuales representan a distintos elementos tales como imagenes, datos, personas, y todo lo que sea buscable. Su estructura de datos consiste de nodos y bordes (edges) para conectar a los nodos entre si.
Como mencionamos, en la estructura de dato de la grafica los nodos representa a una entidad y esta puede ser cualquier elemento buscable como personas, imagenes, productos, etc. Los edges representan a las conexiones entre ellos, y a su vez cada nodo puede tener mas de una conexion. Tomemos el ejemplo que buscamos al inicio..
Supongamos que en un principio tenemos dos nodos con las palabras C++ y Debian. Y despues podemos agregar dos nodos mas, uno con la palabra Lenguaje y otro con Distro Linux. Ahora podemos enlazar a C++ con Lenguaje y Debian con Distro Linux, y a su vez podemos enlazar a C++ con Debian como S.O. donde poder usarlo, veamos un diagrama de como puede ser:

Ya tenemos una serie de nodos que estan relacionados entre si y uno con otros. Tomemos el nodo Lenguaje, y agreguemos dos nodos mas relacionados a este como pueden ser Java y Python. Ambos son lenguajes pero no tienen mucho en comun con respecto a C++, pero seria una buena opcion recomendarlos? Si y no, porque pueden tener algunos puntos en comun pero no necesariamente estar intrisicamente relacionados entre si. Pero como podemos hacer para que sean una recomendacion convincente? Tomemos que los tres comparten el OOP, Programacion Orientada a Objetos, y por lo tanto los podemos unir con ese nodo. Veamos como sera ahora el nuevo diagrama:
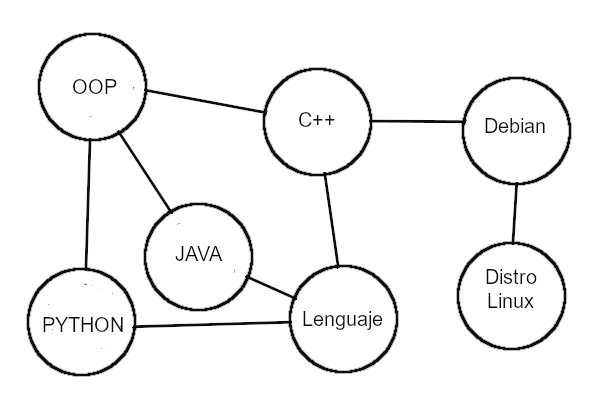
Bueno, tenemos a Java y Python compartiendo que son lenguaje y se puede aplicar el OOP pero uno tendra mas cosas en comun que el otro. Para mejorar esto, usualmente se utiliza en los edges un ranking para poder dar una mejor referencia entre los distintos nodos. Por ejemplo, podemos usar un rango de 0 a 100 para establecer cual tiene una relacion mas fuerte. Si miramos el diagrama anterior, podemos establecer un ranking mas alto entre C++ y Java a traves de Lenguaje asi como tambien OOP pero tambien el ranking de C++ con Python puede ser mas bajo con respecto a Java pero mas alto con respecto a otros, como puede ser Basic. Supongamos que agregamos otros nodo pero ahora para ML.
En este caso, si el ranking entre C++ y Python sera mas fuerte que con Java porque como mencionamos en posts anteriores, hoy en dia son los lenguajes mas utilizados para ML (Machine Learning). Uno por su gran flexibilidad y adaptabilidad como es Python pero C++ no solamente comparte las mismas caracteristicas sino que tambien agrega una caracteristica mas como es una mejor performance. Por esto, si hicieramos una busqueda mas orientada a ML nos daria una recomendacion mas orientada por este lado. Este ranking usualmente se lo denomina como peso, y suele usarse como expresion que un borde o edge tiene mas peso que otro.
En resumen, hoy hemos visto conceptualmente un engine de recomendacion, que es, como trabaja, asi como sus similitudes con un engine de busqueda, y por que se complementan. Espero les haya resultado de utilidad sigueme en tumblr, Twitter o Facebook para recibir una notificacion cada vez que subo un nuevo post en este blog, nos vemos en el proximo post.


Donación
Es para mantenimento del sitio, gracias!
$1.50


